主页 > 苹果版imtoken > 北京大学肖震老师《区块链技术与应用》笔记
北京大学肖震老师《区块链技术与应用》笔记
需要记住的是,在比特币和以太坊中,交易保存在区块内,一个区块可以包含多个交易。 区块链由区块组成,而不是由交易组成。
思考如何组织账户的数据结构 我们能不能像BTC一样把哈希表的内容组织成Merkle Tree?
但是当一个新的区块发布时,哈希表的内容会发生变化,重新组织成新的Merkle Tree? 如果是这样的话,每产生一个新区块就必须重新组织Merkle Tree(ETH中一个新区块的产生时间大约是10s),显然这是不现实的。
需要注意的是,比特币系统中没有账户概念,交易由区块管理,区块包含的交易上限约为 4000 笔,因此 Merkle Tree 不会无限增长。 在ETH中,Merkle Tree是用来组织账户信息的,很明显它会越来越大。
实际上,只有一小部分数据发生了变化。 我们每次都重新构建Merkle Tree,成本非常高,所以我们不需要哈希表,直接使用Merkle Tree。 每次修改只需要修改其中的一部分。 这个可以吗? ?
实际上,Merkle Tree 并没有提供高效的搜索和更新解决方案。 此外,所有的账户都构建成一个大的Merkle Tree,必须对其进行排序,以保证所有节点的一致性和搜索速度。 那么排序之后,是否可以使用Sorted Merkle Tree呢?
新添加的账户,由于其地址是随机的,插入Merkle Tree时很可能处于树的中间,发现后必须重建。 因此,Sorted Merkle Tree 的插入和删除(实际上可能不删除)的成本太高了。
既然没有哈希表和Merkle Trees,那我们就来看看以太坊实际采用的数据结构:MPT。
注:在BTC系统中,虽然各个节点构建的Merkle Tree不一致(未排序),但最终获得记账权的节点的Merkle Tree是有效的。
一个简单的数据结构——trie(字典树、前缀树)
下面是一个由5个词组成的trie数据结构(只画出key,不画出value)
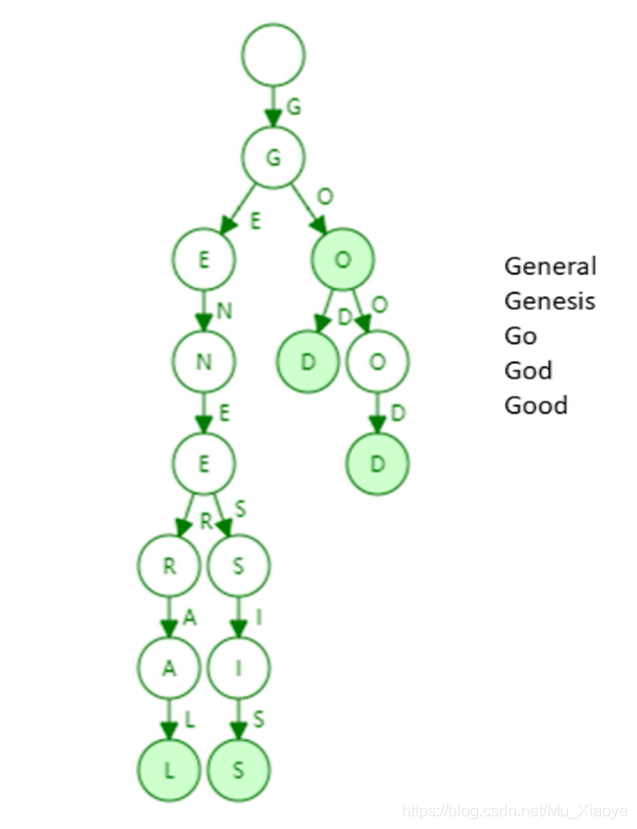
特征:
trie中每个节点的分支数取决于Key值中每个元素的取值范围(图中最多26个英文字母分支+一个结束标志)。 Trie 查找效率取决于键的长度。 在实际应用中(以太坊地址长度为160byte)。 理论上hash会发生碰撞,但trie不会发生碰撞。 给定输入,无论插入顺序如何,构造的trie都是相同的。更新操作的局部性更好
那么有什么缺点可以尝试吗? 当然还有:
Trie 存储浪费。 很多节点只存储一个key,而他们的“儿子”却只有一个,太浪费了。 因此,为了解决这个问题,我们引入帕特里夏树/triePatricia trie(帕特里夏树)
Patricia trie 是具有路径压缩的 trie。 如上例所示,进行路径压缩后,如下图所示:
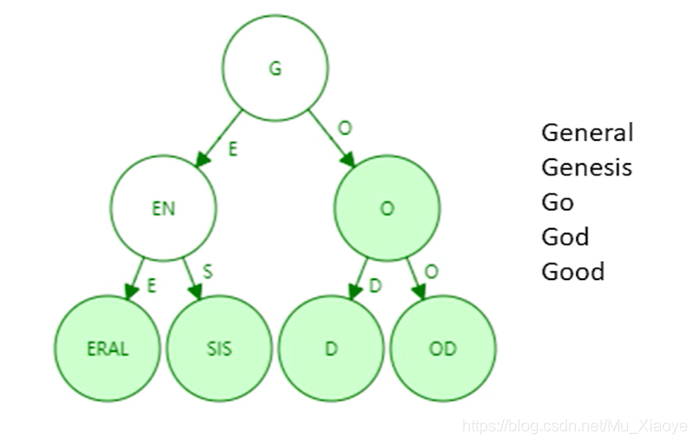
需要注意的是,如果插入了一个新词,可能需要对原来的压缩路径进行扩展。 那么,应该在什么情况下路径压缩效果比较好呢? 当树中插入的键值分布比较稀疏时,可以看出路径压缩效果较好。
在以太坊系统中,有 2^160 种 160 位地址。 这个数字其实很大。 与账户数量相比,可以认为地址的键值非常稀疏。
因此,我们可以在以太坊账户管理中使用帕特里夏树数据结构! 但实际上,以太坊中使用的并不是简单的PT(Patricia tree),而是MPT(Merkle Patricia tree)。
默克尔树和平衡树:
区块链和链表的区别在于,区块链使用哈希指针,而链表使用普通指针。
同样,与Balance Tree相比,Merkle Tree也将普通指针替换为哈希指针。
因此,在以太坊系统中,可以将所有账户组织成一棵经过路径压缩排序的默克尔树,其根哈希值存储在区块头中。
BTC系统中只有一棵由交易组成的Merkle Tree,而以太坊中有三棵(三棵树)。
也就是说,在以太坊的区块头中,存在三个根哈希值。
根哈希值的用处:
防篡改。 提供Merkle证明,可以证明账户余额,轻节点可以验证。 证明有交易的账户中是否存在MPT(Modified Patricia tree)
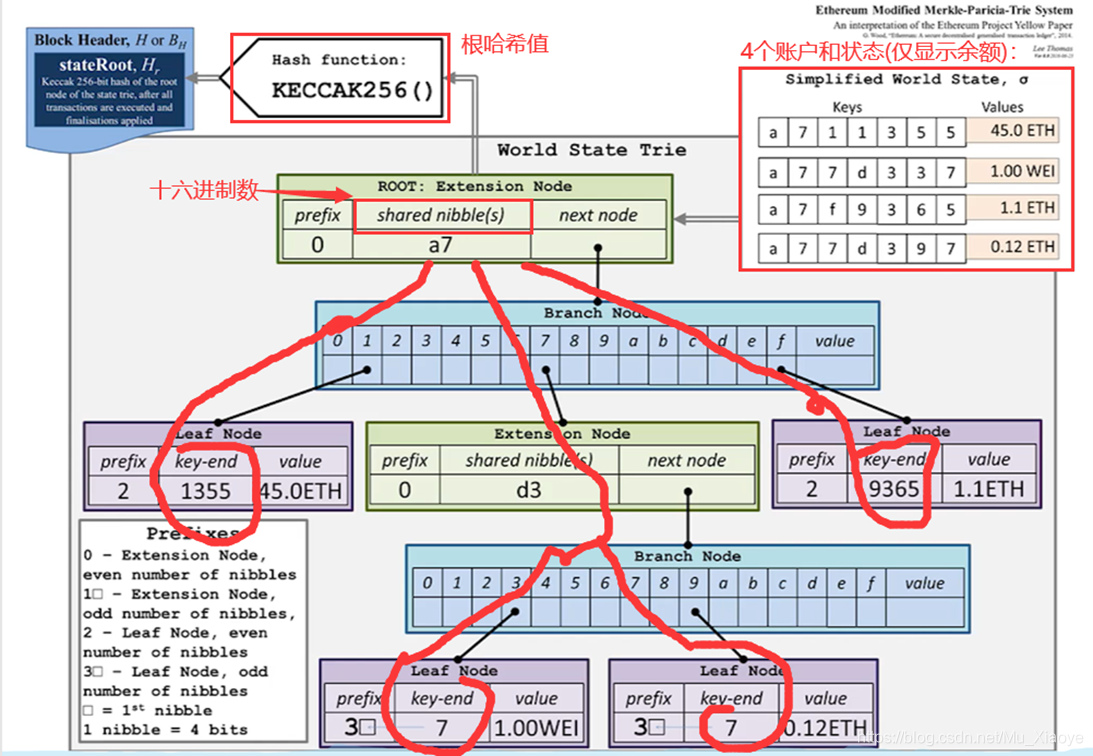
MPT(Merkle Patricia tree)在以太坊进行了修改,我们称之为MPT(Modified Patricia tree)
下图是以太坊中使用的 MPT 结构示意图。 右上角显示四个账户(为直观显示而少)及其状态(仅显示账户余额)。 (需要注意的是这里的指针都是hash指针)

每发布一个新的区块,状态树中某些节点的状态就会发生变化。 但是改变不是原地修改,而是创建一些分支,保持原来的状态。 如下图所示哈希值btc,只需要修改新变化的节点,其他未修改的节点直接指向上一个区块中对应的节点。
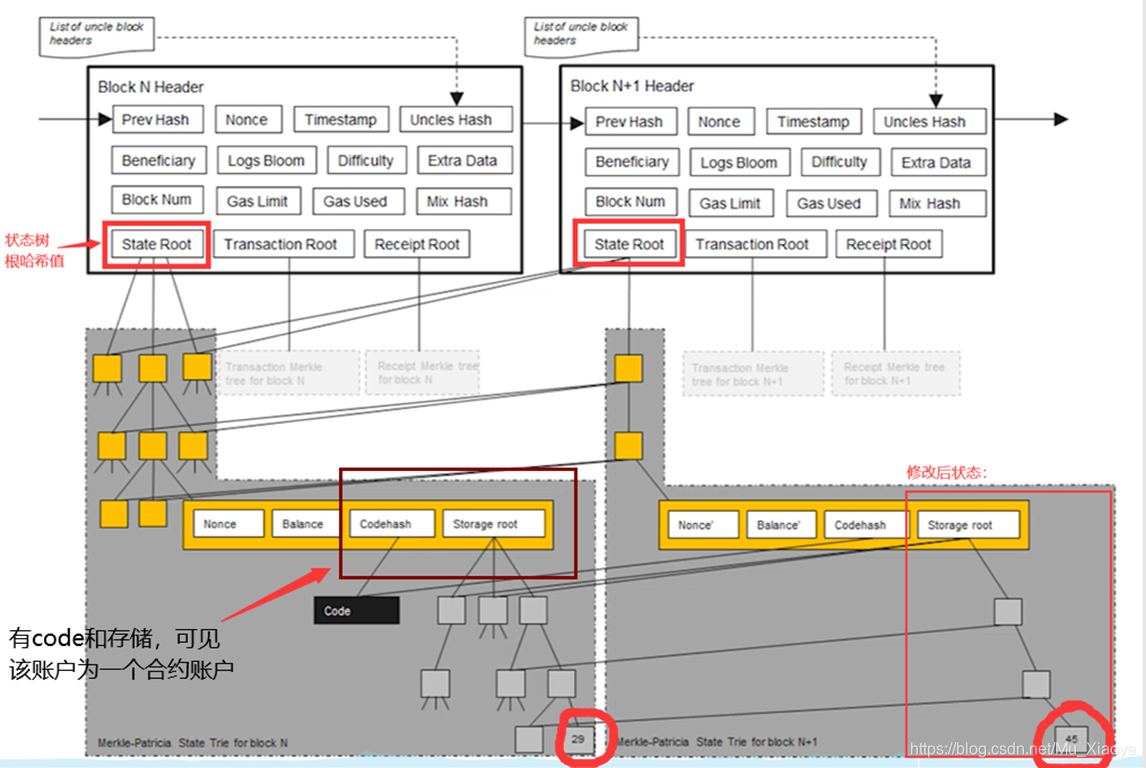
因此,系统中的全节点并不维护一个MPT,而是在每次发布新区块时创建一个新的MPT。 只是大多数节点共享。
为什么要保留原始状态? 为什么不直接修改呢?
为了方便回滚。 后面1发生fork,然后上层节点获胜,变成2中的状态,那么后面节点对状态的修改需要回滚。 因此,需要维护这些历史记录。
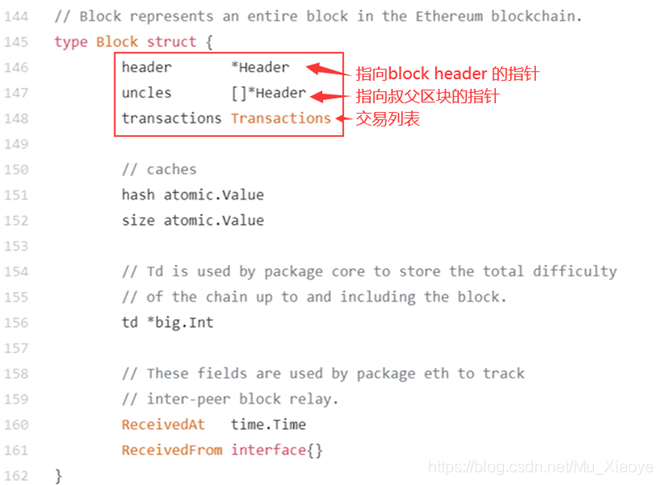
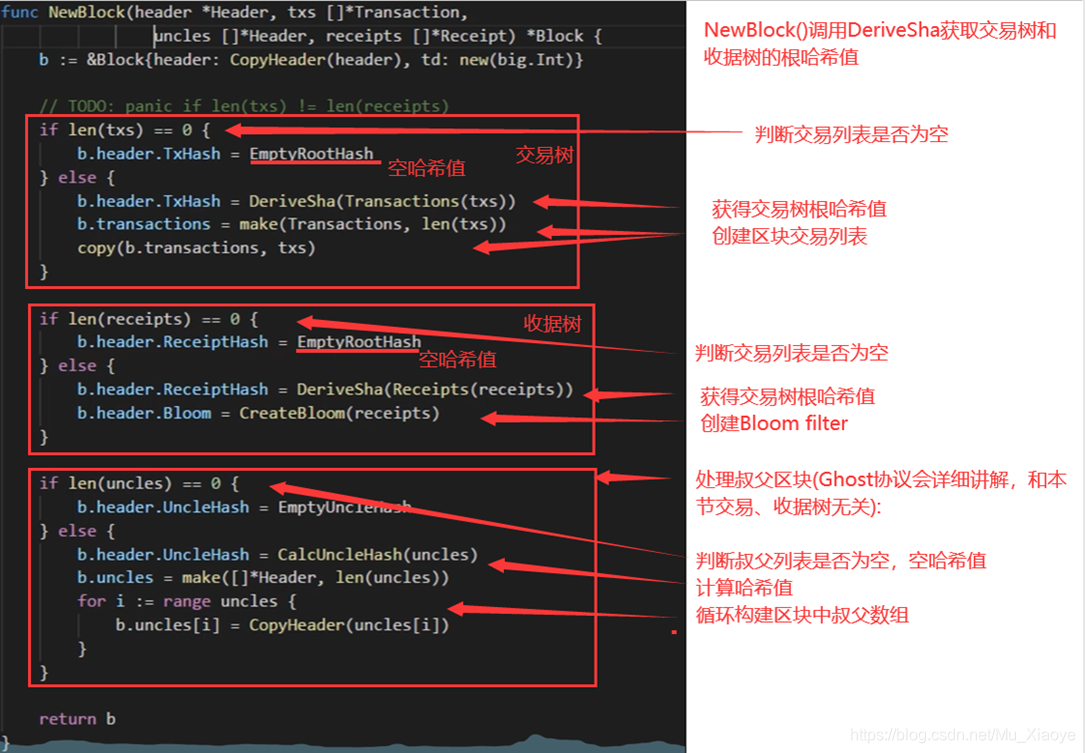
通过代码看以太坊中数据结构block header中的数据结构

块状结构
区块真正上线时的信息

最后说明
键值对保存在状态树中,键为地址,值状态通过RLP(Recursive Length Prefix,序列化的一种方法)编码序列号后保存。
交易树和收据树
每发布一个区块,区块中的交易就会形成一棵Merkle Tree,也就是交易树。 此外,以太坊还增加了收据树,每笔交易执行后形成一张收据,记录交易相关信息。 也就是说,交易树上的节点和收据树上的节点是一一对应的。
由于以太坊智能合约的执行较为复杂,通过添加收据树,可以方便快速查询执行结果。
交易树和收据树都是M(Merkle)PT,而BTC中使用的是普通的MT(Merkle Tree)。 (也许它只是为了三叉树代码重用而设计的)
MPT的优点是支持查找操作,可以通过键值沿树查找。 对于状态树,查找键值为账户地址; 对于交易树和回执树,查找键值为交易在已发布区块中的序号。
交易树和回执树只组织当前区块中的交易,而状态树包括所有账户的状态,不管这些账户是否与当前区块中的交易相关。
多个区块状态树共享节点,而交易树和回执树按区块独立。
交易树和收据树的用途:
为轻节点提供默克尔证明。 更复杂的搜索操作(例如:查找近十天的交易;近十天的众筹事件等)布隆过滤器(Bloom filter)
支持更有效地查找元素是否在集合中
最笨:元素遍历,复杂度为O(n)——不能使用轻节点
方法:给定一个大集合,计算一个紧凑的“摘要”,
例子:如下图所示,给定一个数据集,意义元素a、b、c通过哈希函数H()计算得到,并映射到一个128位向量的某个值,其初始值为所有0.位置,将这个位置设置为1。所有元素处理完后,可以得到一个向量,称为原始集合的“汇总”。 可以看出,“摘要”比原始集合小得多。
假设要查询一个元素d是否在集合中,假设H(d)映射到向量的位置为0,说明d一定不在集合中; 假设H(d)映射到vector的位置为1,则集合中可能确实存在d,也可能因为hash冲突而出现误报。
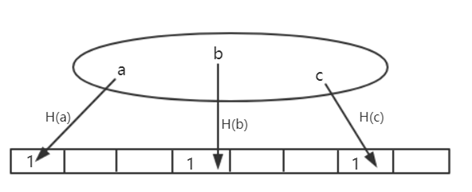
Bloom filter 特点:可能有误报,但不会有误报。

布隆过滤器变体:使用一组哈希函数进行向量映射,有效避免哈希冲突
集合中删除元素怎么办?
无法操作。 也就是说,简单的布隆过滤器不支持删除操作。 如果要支持删除操作,需要将记录数从0和1改为一个计数器(需要考虑计数器会不会溢出)。
布隆过滤器在以太坊中的作用
每笔交易完成后,都会生成一张收据,收据中包含一个布隆过滤器,用于记录交易类型、地址等信息。 区块头中还包含一个布隆过滤器,它是区块中所有交易的布隆过滤器的联合体。
所以,在查找的时候,先查找区块头中的Bloom filter,如果区块头中包含的话。 然后检查块中包含的交易的布隆过滤器。 如果存在,检查交易以确认; 如果不存在,则表示发生了“碰撞”。
优点是通过布隆过滤器等结构,可以快速过滤掉大量不相关的块,从而提高搜索效率。
补充
以太坊的运行过程可以看作是一个交易驱动的状态机。 通过执行当前块中包含的交易,驾驶系统从当前状态转移到下一个状态。 当然,BTC也可以看作是一个交易驱动的状态机,其状态为UTXO。
对于给定的当前状态和给定的一组事务,可以确定性地转换到下一个状态(保证系统一致性)。
问题一:A向B转账时,是否有可能收款账户不在状态树中?
可能的。 因为以太坊中的账户可以由节点自己生成,只有在交易产生时才会被系统知道。
问题2:是否可以将每个区块中的状态树改为只包含区块中与交易相关的账户状态? (显着减小状态树的大小并与交易树和收据树保持一致)
不能。 首先,在这种设计中查找账户状态很不方便,因为没有包含所有状态的区块。 其次,如果你想转账到一个新创建的账户,你需要知道收款账户的状态,然后才能添加金额。 但是由于是新创建的账户,需要一直找到创世块才能知道该账户是新创建的账户。 该系统不存储在区块链中,由区块链不断扩展。
代码中的具体数据结构
根据这个通用demo,可以看到它的创建过程。 肖老师的视频中,也有对bloom filter等具体结构的分析,这里不再赘述。 有兴趣的可以直接看肖老师的视频。 代码解析从视频29:00开始,可直接点击本文顶部链接。
ETH 中的 GHOST 协议
BTC 系统的出块时间为 10 分钟,而以太坊的出块时间缩短为 15 秒左右。 虽然系统响应时间和吞吐率得到有效提升,但也导致系统临时分叉成为常态,分叉数量增加。 许多。 这对共识协议来说是一个巨大的挑战。 在BTC系统中,不在最长合法链上的节点最终会失效,但在以太坊系统中,如果这样做,由于系统经常出现分叉,矿工很可能会无法开采。 它将被废弃,这将大大降低矿工的挖矿积极性。 对于个体矿工而言,与大型矿池相比存在天然劣势。
对此,以太坊设计了一个新的公式协议——GHOST协议(该协议并非原创,而是对原有Ghost协议的改进)。
GHOST协议 GHOST协议初始版本
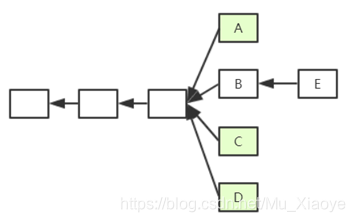
如图所示,假设以太坊系统存在以下情况。 A、B、C、D 在四个分支上。 最后,随着时间的推移,B所在的链成为最长的合法链,于是区块A、C、D全部失效。 但是为了补偿这些区块所属的矿工所做的工作,给这些区块一些“补偿”,它们被称为“Uncle Blocks”(叔块)。
规定区块E在发布时可以包含叔块A、C、D,叔块A、C、D可以获得区块奖励的7/8。 为了鼓励E包含叔块,规定每包含一个叔块可以获得额外1/32的区块奖励。为了防止E包含大量叔块,规定一个块可以最多只包含两个叔块,所以E最多只能包含A、C、D中的两个块作为自己的块奖励
假设一个矿工挖出了B,他沿着他所在的链继续挖,他知道A和自己是“同代”,那么他可以把A纳入区块挖矿,如果他在区块中听到C挖矿过程 如果你也是“peer”,你可以停止挖矿,将C包含进来,重新组织成一个新的区块重新挖矿。 实际上,由于挖矿过程的无记忆特性,这不会降低挖矿成功的概率。
初始版本错误:
因为叔块最多只能包含两个,如果图中有三个怎么办? 矿工自私,故意不包含叔块,导致叔块7/8的区块奖励损失,自己只损失了1/32。 如果两个大矿池A和B之间存在竞争关系,他们可以使用故意不包含对方的叔块,因为对自己的损失小,对对方的损失大。 新版Ghost协议
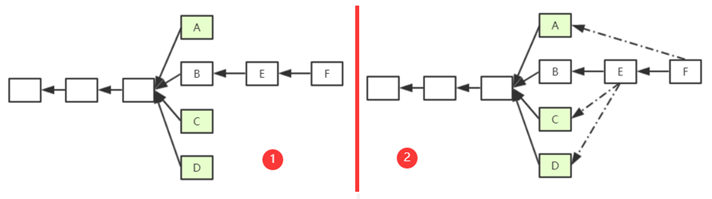
下图中的1是对上例的补充,F是E之后的新块。因为规定E最多只能包含两个叔块,所以假设E包含C和D。此时,F也可以把A当成自己的叔叔块(其实不是叔叔那一代,而是爷爷那一代)。 如果继续往下挖,F之后的新块仍然可以包含B的同行的块(假设E和F还没有包含)。 这样就有效解决了原版Ghost协议存在的上述不足。
但是这种方式仍然存在一定的问题。

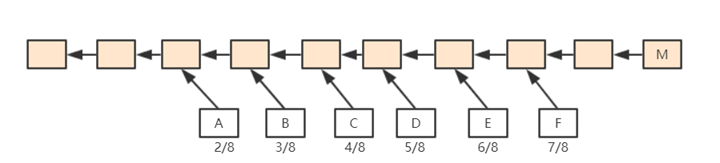
我们把“叔叔”的概念扩展一下,但问题是,“叔叔”的定义应该是几代人?
如下图,M是区块链上的一个区块,F是它严格意义上的叔叔,E是它严格意义上的“祖父”。 以太坊中规定,如果M包含F代区块,则F将获得7/8的区块奖励; 如果 M 包含 E 代区块,则 F 将获得 6/8 的区块奖励,以此类推。 直到A代区块被包含,A获得2/8的区块奖励,之前的“叔块”对于M不再被认为是M的“叔块”。
对于M来说,无论涉及哪一代“叔叔”,区块奖励都是1/32的区块奖励。
换句话说,叔块的定义是它与当前块有七代以内的共同祖先(合法的叔块只有6代)。
这样方便所有节点记录。 此外,该协议还鼓励一旦发生分叉就合并。
以太坊奖励:
BTC:静态奖励(区块奖励)+动态奖励(交易手续费,比例小)
ETH:静态奖励(区块奖励+包含叔块的奖励)+动态奖励(油费,占比较小,叔块不占)
比特币为了人为制造BTC的稀缺性,每隔一段时间就会降低区块奖励,最终当区块奖励趋于0时,主要依靠交易手续费来运作。 然而,以太坊并没有人为规定定期减少区块奖励。
叔块包含在以太坊中。 您想将交易包含在叔块中吗?
不,主链上的叔块和兄弟块可能包含冲突交易。 而且我们前面也提到了,叔块是没有动态奖励的。 因此,当一个节点收到一个叔块时,它只检查块的有效性,而不检查其中交易的有效性。
当然,分叉后的表弟块呢? 比如下图,链A->F并不是最长的合法链,那么区块B->F呢? 挖矿该不该补偿?
如果规定整个following chain整体奖励出块,这在一定程度上鼓励了分叉攻击(降低了分叉攻击的成本,因为即使攻击失败也会有奖励)。 因此,ETH系统规定,只有区块A被认定为叔块,并给予补偿,后续所有区块均无效。

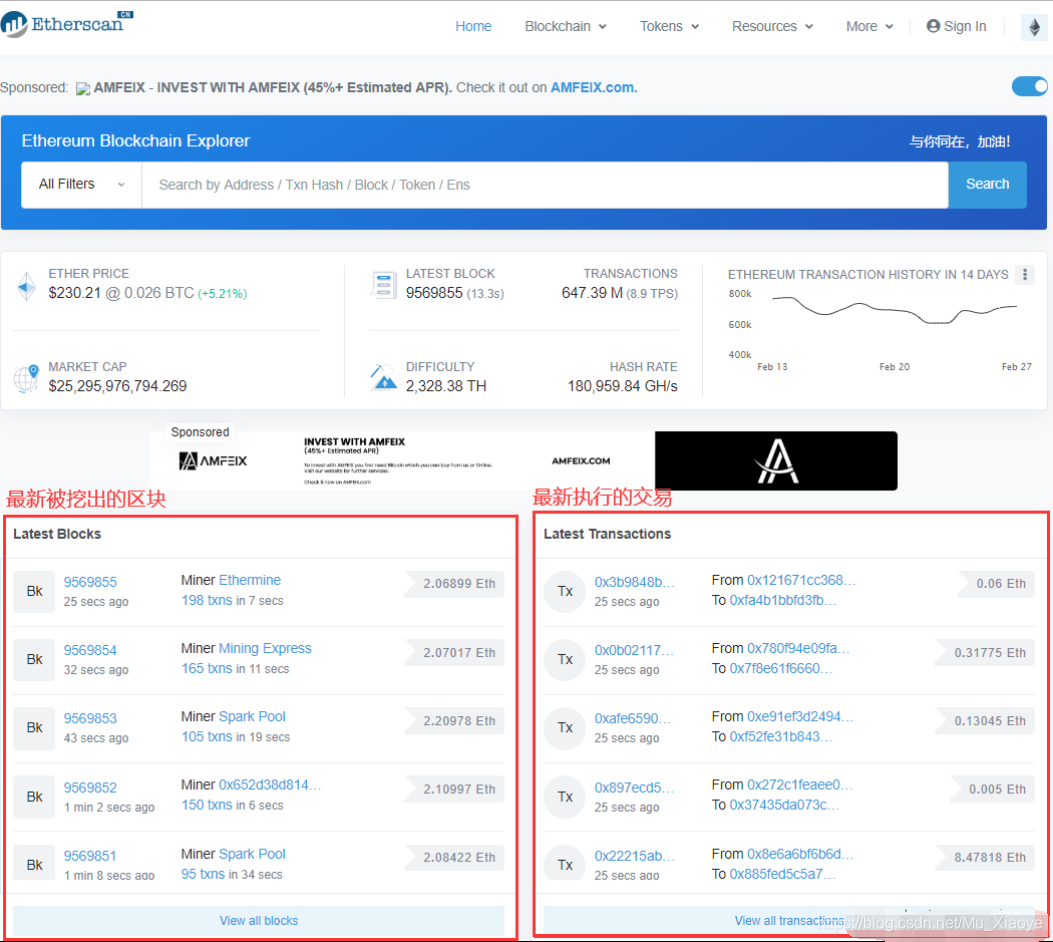
以太坊真实数据
Etherscan 网站,可以实时查看以太坊的数据。 以下截图是本人于2020年2月28日截取的,与肖先生视频中的截图有一些差异。 但具体内容基本相同。
Chome浏览器中文翻译页面:
视频中肖老师还根据网站上的区块信息分析了GHOST协议中的叔块奖励等信息,这里不再赘述。
ETH 挖矿算法第 1 部分
在之前的BTC章节中,介绍了比特币系统中使用的挖矿算法。 虽然挖矿的过程并没有创造任何实际价值,但挖矿本身维护了比特币系统的稳定性。 总的来说,比特币系统中的挖矿算法还是比较成功的,没有发现大的漏洞。
当然,比特币系统的挖矿算法也存在一定的问题,其中最突出的是导致挖矿设备专业化,普通电脑用户难以参与,从而导致挖矿中心化的局面. 中心化”与这一思想相悖。
因此,在比特币之后,包括以太坊在内的众多加密货币都针对这一缺陷进行了改进,试图实现ASIC Resistance(对ASIC专用矿机的抵抗)。 与普通计算机相比,ASIC芯片的计算能力更强,但内存访问性能差异不大,因此常用的方法是Memory Hard Mining Puzzle,增加了对内存访问的需求。
莱特币(莱特币)
莱特币百度百科:点这里
莱特币中国官网:点击此处
一度,莱特币是市值仅次于比特币的第二大货币。 它的基本设计与比特币基本相同,但针对赛诺菲的挖矿进行了修改。
Litecoin 的拼图基于 Scrypt。 scrypt是一种对内存性能要求很高的哈希函数,之前多用于计算机安全密码学领域。
莱特币挖矿算法的基本思想是设置一个大数组,依次用伪随机数填充。
因为我们无法提前预测哈希函数的输出,看起来像是很多随机数据,所以被称为“伪随机数”。
Seed是种子节点,通过对Seed进行一些操作得到第一个数,然后每个数通过前一个位置的值哈希得到。
可以看出这样一个数组中的值之间存在着前后依赖关系
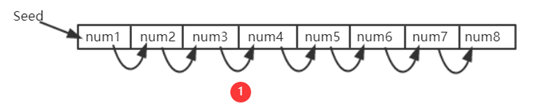
2.当需要解Puzzle时,伪随机顺序从数组中读取一些数字,每个读取的位置都与前一个数字相关联。 例如:第一次从A位置读取数据,根据A中的数据计算下一次读取位置B; 第二次从B位置读取数据,根据BC中的数据计算下一个读取位置;
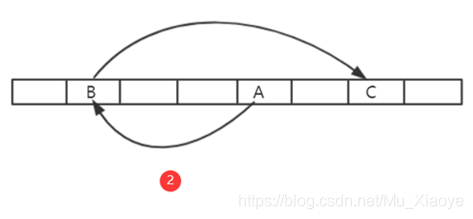
分析
如果数组足够大,对于矿工来说,必须保存数组以便查询,否则每次不仅要计算位置,还要根据Seed计算整个数组数据,才能查询到该数组的数据相应的位置。 对于矿工来说,计算复杂度显着增加。
当然,矿工可以选择只保存一部分数据,例如:只保存奇数位数据,需要偶数位时再根据之前的奇数位数据进行计算,从而减少内存空间的大小减半(计算复杂度增加了一点,但内存减半)。
核心思想:不能只进行计算,增加对内存的访问,从而对ASIC芯片不友好。
这个IDEA有问题吗? 看起来还不错,让ASIC矿机挖矿不友好,但是这种方式对Puzzle验证不太友好。 如果要验证Puzzle,还需要存储数组,所以对轻节点不友好(系统中大部分节点都是轻节点)。
因此,对于莱特币的实际应用,数组大小不宜设置过大。 比如:对于电脑来说,1G没有压力,但是对于手机APP来说,1G太占空间了。 因此,在实践中,莱特币系统设计的数组大小仅为128K。 莱特币刚发行时,希望不仅能抗ASIC,还能抗GPU。 但现实中逐渐出现了GPU挖矿,后来也出现了ASIC芯片挖矿。 在实际应用中,莱特币的设计并没有达到预期的效果,也就是说128k对于ASIC Resistance来说太小了。
莱特币的这种设计是好事还是坏事?
从没有起到预期的作用来看,当然是坏事,但换个角度想,这个设计目标的早期公示,有效吸引了大量矿工参与,解决了挖矿问题。莱特币的“启动”。 莱特币仍然是一种更主流的加密货币。
此外,莱特币与比特币的另一个区别是区块生成时间。 莱特币是2.5分钟,是比特币的1/4。 除了这些差异之外,这两种货币基本相同。
以太坊
以太坊的概念与莱特币相同,都是Memory Hard Mining Puzzle,但具体设计与莱特币不同。
以太坊挖矿算法基本思想
在以太坊中,设计了一大一小两套数据集。 小的是16MB缓存,大数据集是1G数据集(DAG)。 关系是1G的数据集是由16MB的数据集生成的。
想想为什么要设计一大一小两个数据集?
为了便于验证,轻节点可以存储16MB的Cache用于验证,而矿工需要存储1GB的大数据集,以便更快地挖矿,减少重复计算。
16MB小Cache数据生成方式与莱特币类似
第一个数字是对Seed进行一些操作得到的,每个数字都是通过对前一个位置的值进行哈希处理得到的。 (不同):大型DAG生成方法:
大数组中的每个元素都以伪随机顺序从小数组中读取一些元素,这与莱特币中的方式相同。 例如第一次读取位置A的数据,则计算当前哈希值更新迭代计算下一次读取位置B,然后进行哈希值更新迭代计算C位置元素。 如此反复读取256次,最后计算出一个数作为DAG中的第一个元素,以此类推,依次类推DAG中各个元素的生成方式。
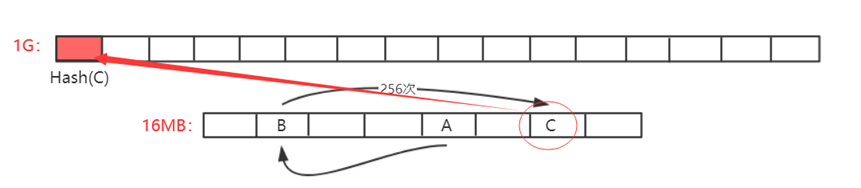
分析
轻节点只保存一小块缓存,只需要在验证时进行计算。 但是对于挖矿来说,如果是这样的话哈希值btc,大部分的算力都花在了通过Cache计算DAG上了。 因此,为了更快地挖矿,它必须保存大量的 DAG。
以太坊挖矿流程:
根据区块头和其中的Nonce值计算一个初始hash,映射到一个初始位置A,读取位置A的数和下一个相邻位置A'的数,根据两者计算下一个位置B 、读B、B'位置的数字,依此类推,反复读64次,共读128个数字。

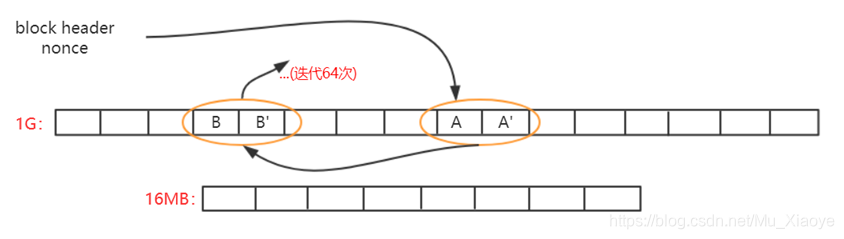
最后,计算一个哈希值,并与挖矿难度目标阈值进行比较。 如果不匹配,则再次替换 Nonce。 重复上述操作,直到最终计算出的哈希值满足难度要求或当前区块被挖出。
ETH挖矿算法第2部分伪代码理解以太坊挖矿算法
目前以太坊的挖矿主要是基于GPU。 可以看出它的设计是比较成功的,这与以太坊设计的挖矿算法(Ethash)需要的大内存有很大关系。
与128K相比,1G大阵列要大8000多倍。 即使是 16MB 也比 128K 大 100 多倍。 可以看出内存需求差距很大(而且两个数组的大小会不断增长)。
当然,除了挖矿算法设计之外,以太坊实现ASIC Resistance还有一个原因,那就是它预期从工作量证明(POW)到权益证明(POS)的转变
股权证明(POS:状态证明)
股权证明:根据持股量通过投票达成共识,类似于股权制的有限共识,根据股份数量进行投票,股权证明不需要挖矿。
对于ASIC矿机厂商来说,这就像悬在他们头上的达摩克利斯之剑。 因为ASIC芯片的开发周期很长,成本很高,如果以太坊转为权益证明,所有这些研发成本都白费了(ASIC矿机只能挖特定的加密货币)
但实际上,以太坊仍然是一种 POW 挖矿共识机制。 在设计之初,以太坊的开发者就设想从 POW 切换到 POS,并埋下了“难度炸弹”,以防止部分矿工不愿意切换。 但截至目前,以太坊仍然基于 POW 共识机制。
其实很多时候,在面对一些问题的时候,我们只要换个思路,就能得到很好的解决办法。 在这里,如果按照最初的思路,通过挖矿算法的不断改进,无疑很难做到ASIC Resistance。 而这里通过不断推动转POS来不断威慑矿工,让矿工不敢擅自转ASIC挖矿,从而实现ASIC Resistance。
预挖(Pre-Mining)
以太坊使用的预挖机制。 这里的“预挖”不是挖矿,而是在开发以太坊时为开发者预留一部分币种。 以太坊的早期开发者现在非常富有。 (致富新思路!果然科技=金钱)
比特币不采用这种模式,所有的比特币都是通过挖矿产生的。 但是早期的挖矿难度很容易,中本聪自己也有很多币(但是没花掉。。。)
与Pre-Mining相对应的还有Pre-Sale。 Pre-Sale 是指出售预留货币用于后续开发,类似于风险投资或众筹。 目前,加密货币的种类很多,其中一些是通过Pre-Sale来获取资金的。 如果这时候买入,如果后面币种成功了,也能得到不少好处,但真正成功的币种只是少数。 这就是它的风险。
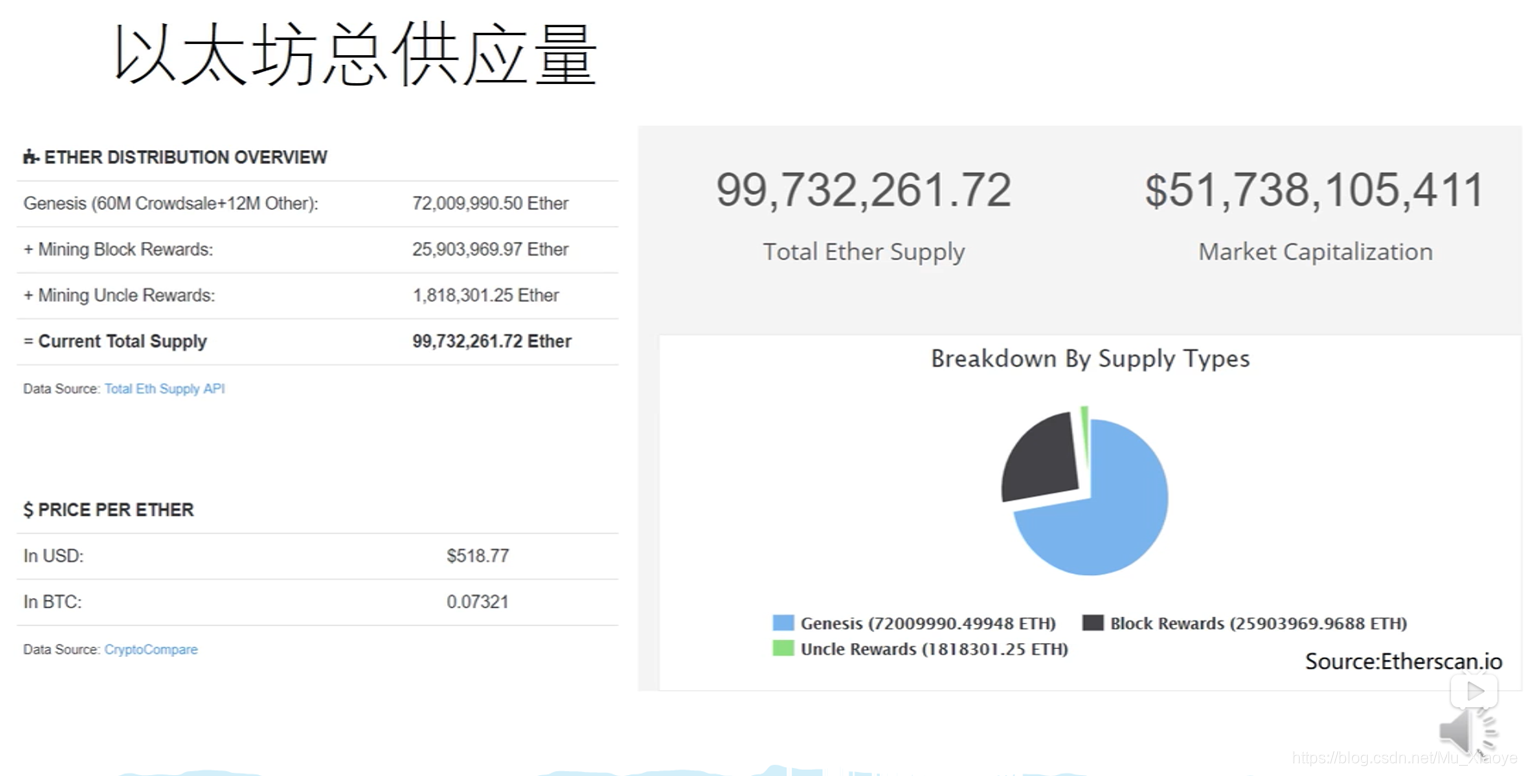
以太坊统计以太坊以太坊供应量(2018 年)
The market value of Ethereum is more than 50 billion US dollars, are you sour?
In the pie chart, the blue part is all produced by Pre-Mining (close to 3/4), which shows how important it is to master technology. The black part is the ether currency generated by the block reward, and the green part is the reward ether currency generated by the uncle block.
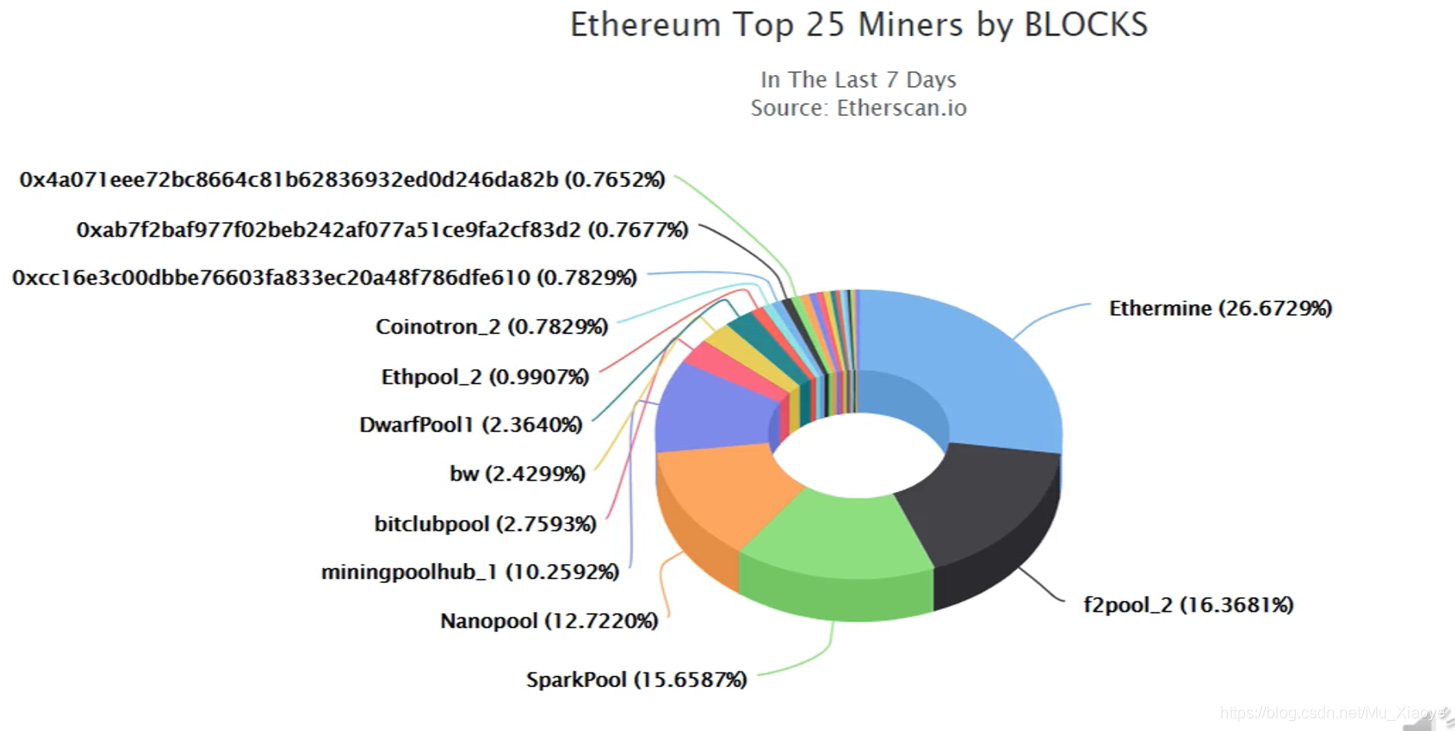
Mining computing power proportion of the largest 25 mining pools (2018)
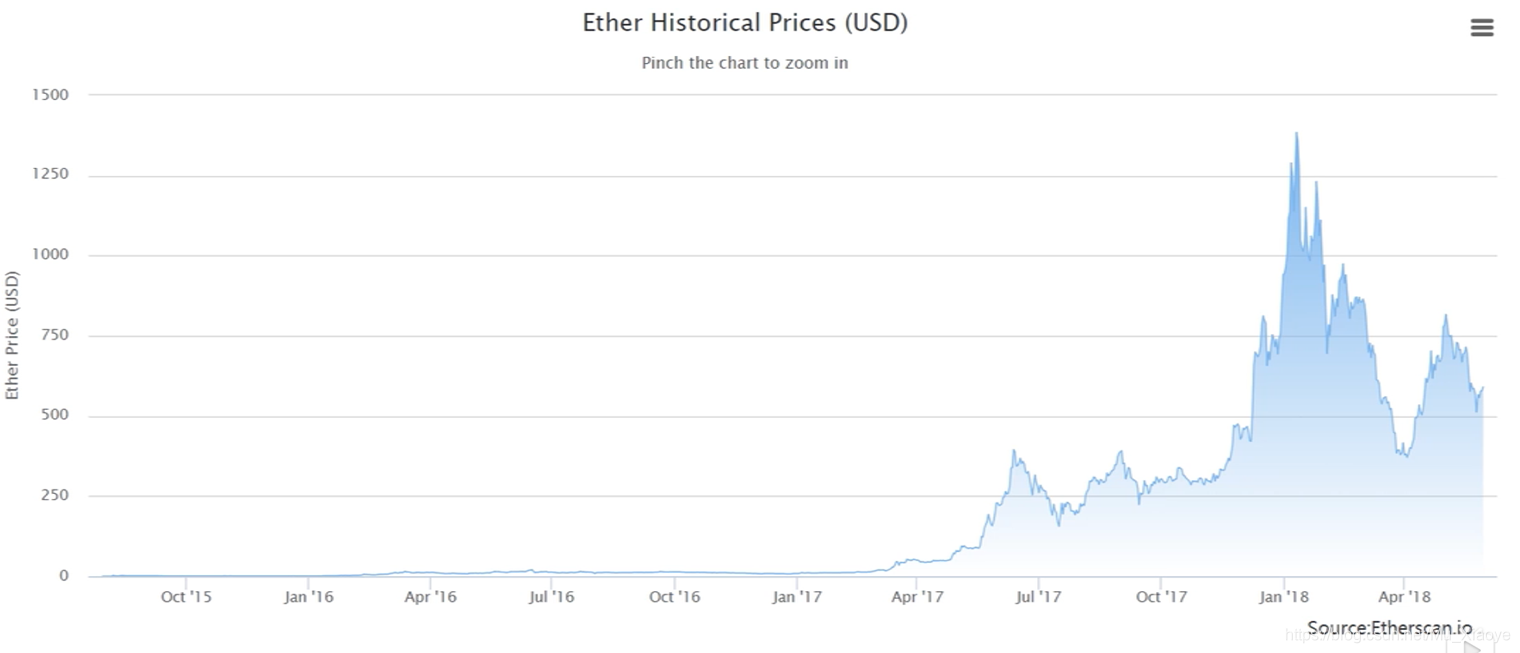
Ether price changes (until 2018)
It can be seen that Ethereum only started to rise sharply in 2017. Do you feel like you missed 100 million?
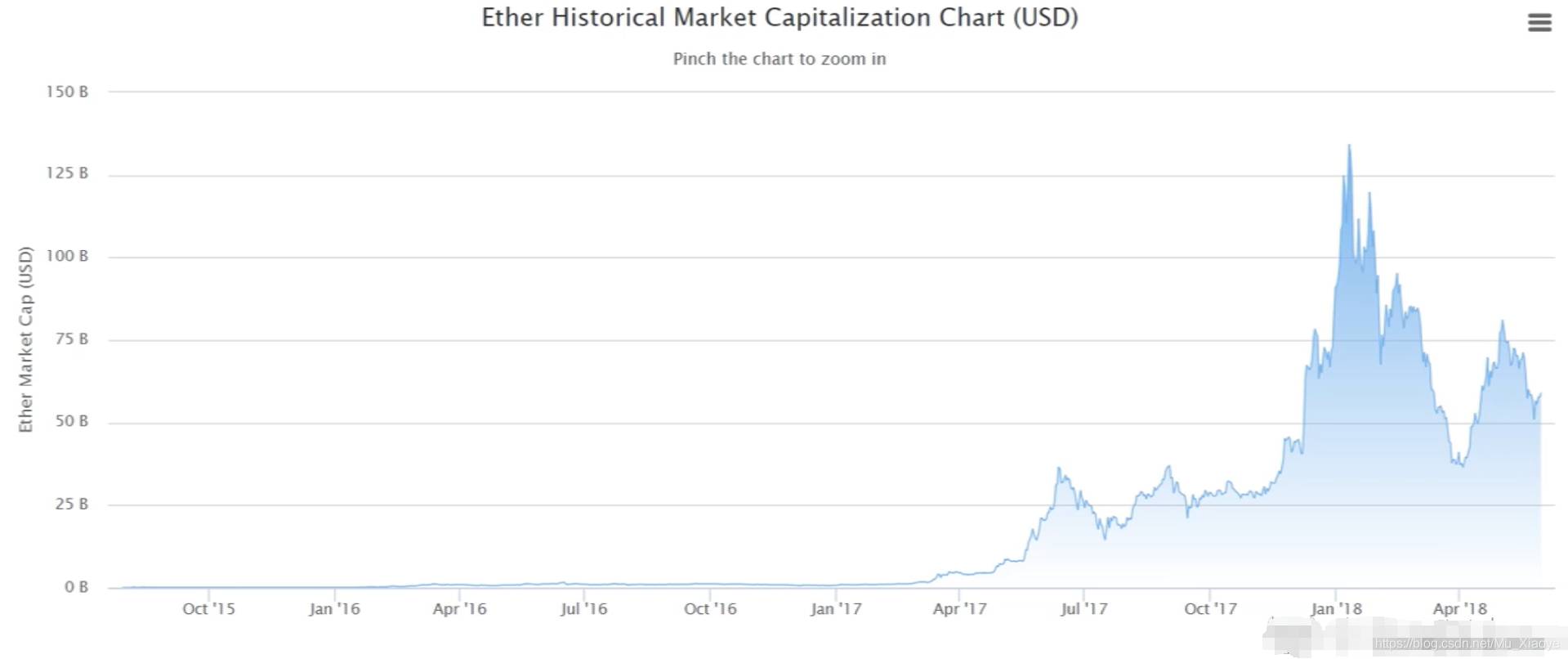
Changes in the market value of Ethereum (until 2018)
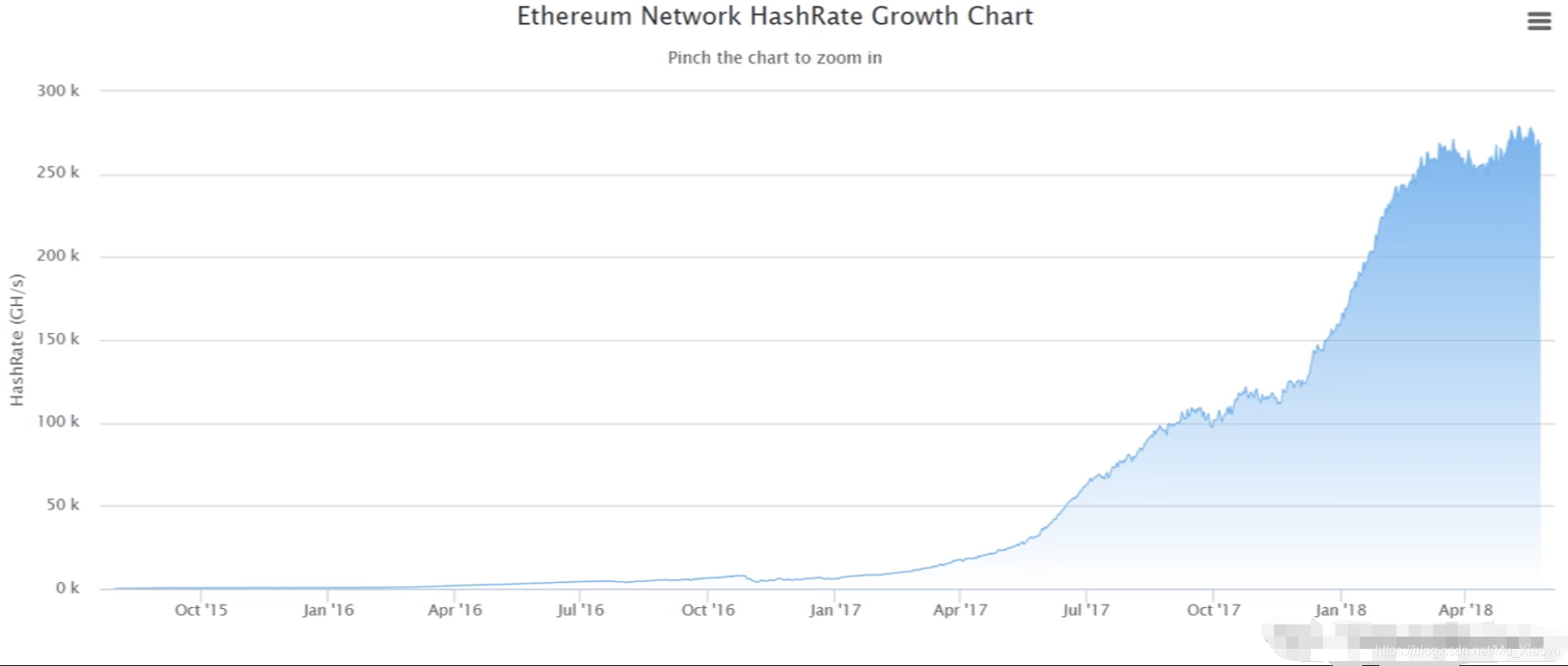
Changes in Ethereum Hash Rate (until 2018)
other points of view
The mining algorithm design in this article has always tended to allow the public to participate, which is only fair. And due to the dispersion of participants and the dispersion of computing power, it further makes the system more secure.
But the same thing has different views from different viewpoints. Some people think that it is not safe to allow ordinary computers to participate in mining. Like Bitcoin, it is safe to allow centralized mining pools to participate in mining. 为什么?
Because in order to attack the system, it is necessary to purchase a large number of mining machines that can only mine specific currencies and carry out a forced 51% attack through computing power. After the attack is successful, the value of the currency will inevitably plunge, and the hardware cost invested by the attacker will be All in vain. And if general-purpose computers are allowed to participate in mining, the cost of launching an attack will be greatly reduced. At present, large Internet companies can gather their servers to attack, and after the attack is completed, these servers can still turn to run daily business. Therefore, some people think that in terms of mining, ASIC mining machines "dominate the world" is the safest way.